

What is the purpose of Bert?
Contents
BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context. The BERT framework was pre-trained with text from Wikipedia and can be fitted with question and answer data sets.
BERT is important as it tries to ensure that the intent behind the user’s query is fully understood so that the most relevant searches can be given to the user. Because of this, people will be able to quickly find the relevant information they are looking for.
BERT will help with things like:
- Determination of named entity.
- Prediction of the next sentence of textual implication.
- Coreference resolution.
- Answer to questions.
- Disambiguation of the meaning of words.
- Automatic summary.
- Polysemy resolution.
BERT is without a doubt a breakthrough in the use of machine learning for natural language processing. The fact that it is accessible and allows quick fine tuning will likely allow for a wide range of practical applications in the future.
Is Bert better than Lstm?
Because BERT practices predicting missing words in the text, and because it parses each sentence without a specific direction, it does a better job of understanding the meaning of homonyms than previous NLP methodologies, such as NLP methods. incrustation.
The fundamental NLP model used initially is the LSTM model, but due to its drawbacks, BERT became the preferred model for NLP tasks.
BERT is based on the Transformer architecture. It is a deep bidirectional deep neural network model. BERT’s key technical innovation is applying Transformer’s bidirectional training to language modeling.
We can say that when we go from RNN to LSTM we are introducing more and more control knobs, which control the flow and mixing of inputs according to the trained weights. And thus it provides more flexibility to control outputs. So LSTM gives us the most controllability and therefore the best results.
Why transformers are better than Lstm?
Long story short, Transformers are better than all other architectures because they totally avoid recursion, processing sentences as a whole and learning relationships between words thanks to multi-headed attention mechanisms and positional embeddings.
Some people have claimed that transformers actually scale faster than linear time with respect to processes. Training on 2 GPUs is claimed to be 3 times faster than training on a single GPU. According to the original article on LSTM, in theory, LSTMs can capture dependencies as distant as 1000.
Like LSTM, Transformer is an architecture to transform one sequence into another with the help of two parts (encoder and decoder), but differs from previously described / existing sequence-to-sequence models because it does not involve recurring networks (GRU, LSTM, etc.).
Therefore, the main advantage of Transformer NLP models is that they are non-sequential, which means that, unlike RNNs, they can be more easily parallelized and that increasingly large models can be trained by parallelizing training.
BERT is a transformer. A transformer is made of several similar layers, stacked one on top of the other. Each layer has an input and an output. So the output of layer n-1 is the input of layer n. The hidden state you mention is simply the result of each layer.
BERT base: 12 layers (transformer blocks), 12 attention heads and 110 million parameters. BERT Large – 24 layers, 16 attention heads and 340 million parameters.
1 answer. Yes, this is correct, but keep in mind that there are two abandonment parameters and that you are using a specific Bert model, which is BertForSequenceClassification.
BERT uses three embeddings to calculate the input representations. They are token embeds, segment embeds, and position embeds. â € œ CLSâ € is the reserved token to represent the beginning of the sequence while â € œSEPâ € separate segment (or phrase).
How does a Bert model work?
Here’s how the research team behind BERT describes the NLP framework: “BERT stands for Bidirectional Encoder Representations from Transformers. … As a result, the previously trained BERT model can be adjusted with just one additional output layer to create state-of-the-art models for a wide range of NLP tasks. ”
2 answers. BERT is deeply bi-directional due to its novel masked language modeling technique. ELMo, on the other hand, uses a concatenation of LSTM from right to left and from left to right and ULMFit uses a unidirectional LSTM. Having a two-way context should, in theory, generate more accurate word representations.
1, BERT achieves an F1 score of 93.2% (a measure of precision), beating the previous state-of-the-art score of 91.6% and the human-level score of 91.2%: BERT also improves the state-of-the-art to 7.6% absolute in the very challenging GLUE benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks.
What can Bert solve?
BERT, which stands for Transformers Bidirectional Encoder Representations, is a neural network-based technique for pre-training natural language processing. In simple language, it can be used to help Google better discern the context of words in search queries.
It’s pre-trained on a large amount of data, so you can apply it on your own (probably small) dataset. It has contextual embeds, so its performance will be quite good. … BERT will continue to revolutionize the field of NLP by providing a high-performance opportunity on small data sets for a wide range of tasks.
Unlike previous models, BERT is a deeply bi-directional and unsupervised language representation, previously trained using only a plain text corpus.
In GLUE, BERT uses “standard sort loss” of log (softmax (CW ^ T)). In other words, this is the log loss (cross entropy loss) of the Softmax layer that takes the class prediction vector corresponding to the BERT token and multiplies it by the weights of the classification layer.
What is the Bert algorithm?
BERT can be used for a wide variety of language tasks, while only adding a small layer to the core model: classification tasks, such as sentiment analysis, are performed similarly to the classification of the following sentence, by adding a classification layer on top of the Transformer Token [CLS] output.
â € œBERT stands for Transformers Bidirectional Encoder Representations. It is designed to pre-train deep two-way representations from unlabeled text by conditioning both left and right context together. … First, it is easy to understand that BERT stands for Bidirectional Encoder Representations from Transformers.
BERT stands for Bidirectional Encoder Representations from Transformers. In short, BERT helps the search engine understand natural language more like humans do.
Because BERT practices predicting missing words in the text, and because it parses each sentence without a specific direction, it does a better job of understanding the meaning of homonyms than previous NLP methodologies, such as NLP methods. incrustation. … So far, it is the best method in NLP to understand texts with a lot of context.
Why is Bert so good?
a. BERT is designed as a deeply bi-directional model. The network effectively captures information from the left and right context of a token from the first layer to the last layer.
BERT is without a doubt a breakthrough in the use of machine learning for natural language processing. The fact that it is accessible and allows quick fine tuning will likely allow for a wide range of practical applications in the future.
BERT and its relative transformer-based GPT-2 have recently proven quite good at sentence-completion tasks (including a modest performance on Winograd challenge sentences) if trained on a large corpus.
2 answers. BERT is deeply bi-directional due to its novel masked language modeling technique. ELMo, on the other hand, uses a concatenation of LSTM from right to left and from left to right and ULMFit uses a unidirectional LSTM. Having a two-way context should, in theory, generate more accurate word representations.
What is Bert fine tuning?
Fitting a BERT model
- Table of Contents.
- Setting. Install the TensorFlow Model Garden pip package. Imports
- The data. Get the data set from TensorFlow Datasets. The BERT tokenizer. Pre-process the data.
- The model. Build the model. Restore encoder weights. Configure the optimizer. …
- Appendix. Recoding a large data set. TFModels BERT on TFHub.
As you can see I only have 22,000 parameters to learn, I don’t understand why it takes so long per epoch (almost 10 min). Before using BERT, I used a classic bi-directional LSTM model with over 1M parameters and it only took 15 seconds per epoch.
Fine tuning, in general, means making small adjustments to a process to achieve the desired result or performance. Deep learning fine tuning involves using weights from a previous deep learning algorithm to program another similar deep learning process.
Now, if we tune, by definition, the weights of the lower level (language representation layer) will change at least a little, that is, the vector of the word will also change (if we compare before and after tuning). That means the meaning of the word changes a bit due to the new task.
Is Bert supervised or unsupervised?
Second, BERT is pre-trained on a large corpus of untagged text that includes the entire Wikipedia (that’s 2.5 billion words!) And Book Corpus (800 million words).
BERT is an open source machine learning framework for Natural Language Processing (NLP). BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context. … BERT is different because it is designed to read in both directions at the same time.
Best of all, the pre-trained BERT models are open source and publicly available. This means that anyone can tackle NLP tasks and build their models on BERT.
BERT, which stands for Transformers Bidirectional Encoder Representations, is a neural network-based technique for pre-training natural language processing.
Why is Bert bidirectional?
BERT stands for Bidirectional Encoder Representations from Transformers. It’s basically a group of stacked Transformer encoders (not the entire Transformer architecture, but just the encoder). … BERT is bi-directional because its layer of self-attention performs self-attention in both directions.
Only in one direction, but not both at the same time. BERT is different. BERT uses bidirectional language models (which is the FIRST). BERT can see both the left and right side of the target word.
The transformer can handle the energy flow in both directions, forward and backward. Actually, this happens in the case of interconnecting transformers. Either winding can become primary (drawing energy from the source) and the other winding becomes secondary, delivering energy to the load. So it is bi-directional.
The difference between base BERT and large BERT is in the number of encoder layers. The base BERT model has 12 encoder layers stacked on top of each other, while the large BERT has 24 encoder layers stacked on top of each other. … The BERT base has 768 hidden layers, while the large BERT has 1024 hidden layers.
Is Bert deep learning?
BERT, which stands for Transformers Bidirectional Encoder Representations, is a neural network-based technique for pre-training natural language processing.
â € œBERT stands for Transformers Bidirectional Encoder Representations. It is designed to pre-train deep two-way representations from unlabeled text by conditioning both left and right context together.
The language model training in BERT is done by predicting 15% of the tokens in the input, which were randomly selected. These tokens are pre-processed as follows: 80% are replaced with a “[MASK]” token, 10% with a random word, and 10% use the original word.
1, BERT achieves an F1 score of 93.2% (a measure of precision), beating the previous state-of-the-art score of 91.6% and the human-level score of 91.2%: BERT also improves the state-of-the-art to 7.6% absolute in the very challenging GLUE benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks.
What does a Bert mean?
BERT, which stands for Transformers Bidirectional Encoder Representations, is based on Transformers, a deep learning model in which each output element is connected to each input element, and the weights between them are dynamically calculated based on their connection.
BURT: backup response team.
noun. a male name, form of Albert, Bertram, Herbert, Hubert, etc.
The feminine hypocoristic of the names that contain the same element is Berta. …
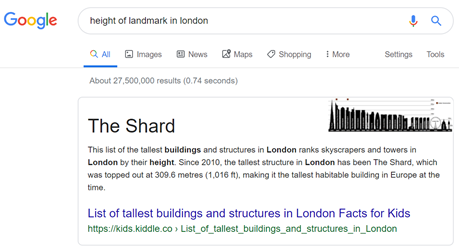
What is RankBrain algorithm?
RankBrain is a component of Google’s core algorithm that uses machine learning (the ability of machines to learn themselves from data inputs) to determine the most relevant results for search engine queries. Pre-RankBrain, Google used its basic algorithm to determine what results to return for a given query.
5 ways SEO experts say you should optimize for RankBrain
- Create irresistible shards. …
- Imitate the professionals. …
- Rethink how content uses keywords (seriously, stop procrastinating) …
- Write conversationally. …
- Decode the ranking factor priorities for your industry.
RankBrain is primarily focused on helping refine the queries Google processes, but the company says the system is also used to help rank web pages. In fact, Google says RankBrain is its third most important ranking factor.
Why did Google introduce RankBrain? RankBrain was initially implemented to satisfy a simple but big problem. Google had not seen 15% of the queries used and as such had no context for them, and no prior analysis to determine whether or not its results were good to satisfy user intent. Enter RankBrain.
Is Siri an AI?
These are all forms of artificial intelligence, but strictly speaking Siri is a system that uses artificial intelligence, rather than being pure AI itself.
Siri, the first virtual personal assistant, grew out of decades of SRI research in artificial intelligence (AI). … In April 2010, Apple acquired Siri, and in October 2011, Siri was introduced as a built-in feature of the Apple iPhone 4S.
Alexa and Siri, the digital voice assistants from Amazon and Apple, are much more than a convenient tool: they are very real applications of artificial intelligence that are increasingly integral in our daily lives.
But is Alexa considered to be an AI? Not as such, but it is certainly a system that uses artificial intelligence technology and techniques to become more intelligent and versatile. In its current form, the system has the following capabilities: Alexa can take interaction signals, note errors, and then connect them.
Is Siri dangerous?
In short, Siri has enabled various ways to circumvent virtually all of Apple’s superior security features, rendering them virtually useless. … As long as they don’t have your passcode, they can’t use Siri vulnerabilities to get your personal information.
According to Apple’s privacy policy, although Siri is listening, it doesn’t remember anything you say before it is triggered by your voice command. … To make sure you get the most appropriate answer, Apple doesn’t completely anonymize your data and leave it on things like location.
And don’t miss the bonus at the end.
- Don’t try to find out if Jon Snow is alive.
- Never tell him to show you skin and household parasites. …
- Don’t look for unfamiliar animals or plants. …
- Don’t ask him to call an ambulance. …
- Don’t tell him you need to hide a body. …
- Don’t tell Siri to call your boyfriend. …
Actually the trick doesn’t work and if you tell Siri “17” you will inadvertently call emergency services. According to the Siri user guide, iPhones automatically call the local emergency number no matter what emergency number you say.
Why is Siri an AI?
Siri is the artificial intelligence-based voice assistant available on all Apple devices, comparable to Amazon Alexa and Google’s Google Assistant. … Siri based on Machine Learning, Artificial Intelligence and intelligence on the device for the operation of intelligent recommendations.
Siri, the first virtual personal assistant, grew out of decades of SRI research in artificial intelligence (AI). … In April 2010, Apple acquired Siri, and in October 2011, Siri was introduced as a built-in feature of the Apple iPhone 4S.
Siri, Cortana, and the Google Assistant are all examples of narrow AI, but they’re not good examples of weak AI, as they operate within a limited predefined range of functions. … In particular, they are not examples of strong AI, as there is no genuine intelligence or self-awareness.
It has transformed many industries and how the information technology industry can be kept away. Apple Inc. is a tech giant that has embraced artificial intelligence as an integral part and is using it as its pitch to consumers. Apple has taken a quieter and smarter approach to AI.
What is the world’s smartest AI?
NVIDIA has developed a new CPU, ‘Grace’, that will power the world’s most powerful AI-capable supercomputer. Grace will be used by the new Swiss National Computing Center (CSCS) system. It is a broad Arm-based data center CPU developed by NVIDIA.
Hanson Robotics’ most advanced human robot, Sophia, personifies our dreams for the future of AI.
Is Google an AI?
Google AI, formerly known as Google Research, is Google’s artificial intelligence (AI) research and development arm for its AI applications.
Siri is the artificial intelligence-based voice assistant available on all Apple devices, comparable to Amazon Alexa and Google’s Google Assistant. … Siri based on Machine Learning, Artificial Intelligence and intelligence on the device for the operation of intelligent recommendations.
In May 2017, Google Brain researchers announced the creation of AutoML, an artificial intelligence (AI) that is capable of generating its own AI. … According to the researchers, NASNet was 82.7 percent accurate in predicting images in the ImageNet validation set.
Is Google an algorithm?
Google’s algorithm does the work for you by searching for web pages that contain the keywords you used to search for, and then assigning a rank to each page based on several factors, including the number of times the keywords appear on the page. … Google refers to this index when a user enters a search query.
The Google search engine is technically complex. There are hundreds (some say thousands) of different factors that are taken into account so that the search engine can determine what should go and where. It is like a mysterious black box, and very few people know exactly what is inside.
How it works: RankBrain is part of Google’s Hummingbird algorithm. It is a machine learning system that helps Google understand the meaning of queries and deliver the best search results in response to those queries. Google calls RankBrain the third most important ranking factor.
As mentioned above, Google’s algorithm partially uses keywords to determine page rank. The best way to rank for specific keywords is by doing SEO. SEO is essentially a way of telling Google that a website or web page is about a particular topic.
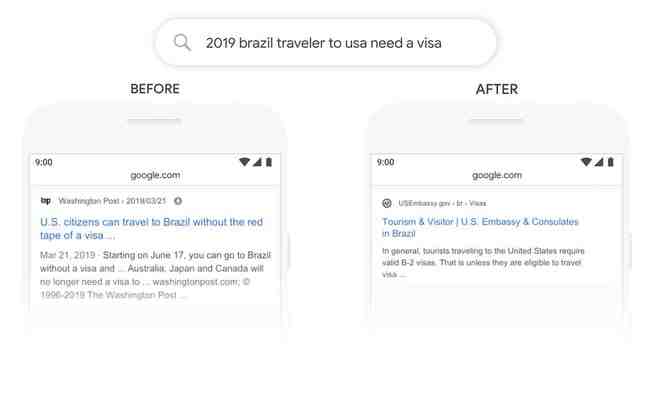
Does Google search use Bert?
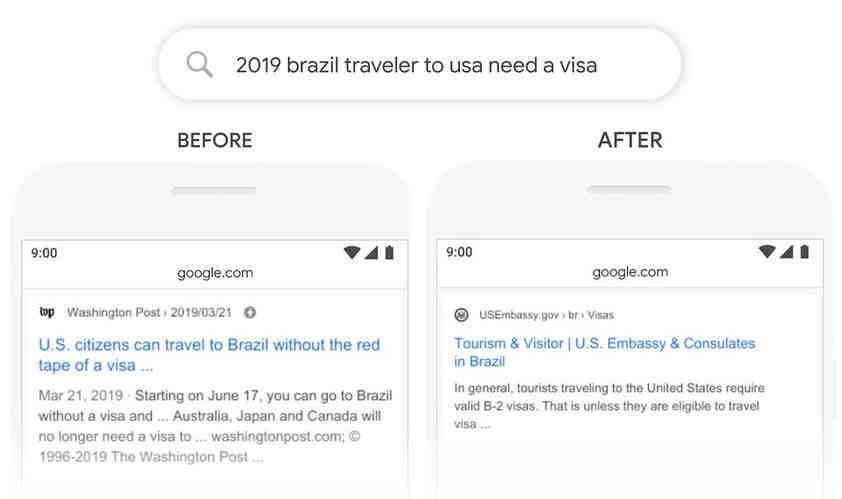
BERT allows the language model to learn the context of words based on the surrounding words rather than just the word that immediately precedes or follows it. Google calls BERT “deeply bi-directional” because contextual representations of words start “from the bottom of a deep neural network.”
Google also applied BERT to improve the quality of the conversation between the Assistant and users. The Google Assistant will now use previous user interactions and understand what is displayed on the screen to answer follow-up questions, helping a more natural conversation.
PageRank (PR) is an algorithm used by Google Search to rank web pages in the results of its search engines. PageRank is a way of measuring the importance of website pages.
Does Google Translate use BERT? Not quite. Like BERT, Google Translate relies on deep neural networks, but the NLP tasks that the two models solve are different: BERT is fundamentally a language model that seeks to model language and predict missing or masked words.
Does Google use natural language processing?
It is based on cutting-edge natural language processing (NLP) techniques developed by Google researchers and applied to their search product over the past 10 months. In essence, Google claims that it is improving results by better understanding how words are related to each other in a sentence.
Editor’s Note: On October 25, 2019, Google officially announced that US search in English now uses & quot; a technique based on neural networks for natural language processing (NLP) & quot; called BERT. Find out more here.
The Google Natural Language API reveals the structure and meaning of text by offering powerful machine learning models in an easy-to-use REST API. You can use it to extract information about people, places, events and much more, mentioned in text documents, news articles or blog posts.
The search engine uses natural language processing (or NLP) to parse the query and notices that there is a proper name in two words in the sentence: Joe Perry. … Then search engines use NLP technology to better understand user intent, it is called semantic search.
What is Google natural language?
An NLP API is an interface to an existing natural language processing model. The API is used to send a text document to the model and receive the model’s output as a return. Google offers an NLP API to various models for different tasks, such as sentiment analysis and text classification.
General description. Videos. The Cloud Natural Language API provides developers with natural language understanding technologies, including sentiment analysis, entity analysis, entity sentiment analysis, content classification, and syntax analysis. This API is part of the larger Cloud Machine Learning API family.
Editor’s Note: On October 25, 2019, Google officially announced that US search in English now uses & quot; a technique based on neural networks for natural language processing (NLP) & quot; called BERT. Find out more here.
The Cloud Natural Language API provides developers with natural language understanding technologies, including sentiment analysis, entity analysis, entity sentiment analysis, content classification, and syntax analysis. … Natural language processing (NLP) is one of the most important technologies of the information age.
What is NLP in search engine?
Natural language search is a search that is carried out in everyday language, asking questions as you would if you were talking to someone. These queries can be typed into a search engine, spoken aloud with voice search, or posed as a question to a digital assistant like Siri or Cortana.
Natural language processing (NLP) research at Google focuses on algorithms that are applied at scale, across all languages, and across all domains. Our systems are used in various ways by Google, affecting the user experience in search, mobile devices, applications, ads, translation, and more.
The NLP engine is the central component that interprets what users are saying at any given time and converts that language into structured inputs that the system can process. … To interpret user input, NLP engines, depending on the business case, use finite state automata models or deep learning methods.
NLP is essentially the process that Google has incorporated to better understand the main keywords or phrases on a page by looking at the content around them. It can be a word directly before and after the “entity” being analyzed, the context of the subsection, or the entire page.
Is English a natural language?
“English is a natural language; Java is a programming language ”. NLP enables clearer person-to-machine communication, without the need for the human to “speak” Java, Python, or another programming language. Programming languages are written specifically for machines to understand.
In neuropsychology, linguistics, and the philosophy of language, a natural language or ordinary language is any language that has evolved naturally in humans through use and repetition without conscious planning or premeditation. Natural languages can take different forms, such as speech or sign.
Some examples of NLP that people use every day are: Spell checker. Autocomplete. Voice text messaging.
Language, system of conventional spoken, manual (signed) or written symbols through which human beings, as members of a social group and participants in its culture, express themselves.
Does Google search use NLP?
Natural language processing (NLP) research at Google focuses on algorithms that are applied at scale, across all languages, and across all domains. Our systems are used in various ways by Google, affecting the user experience in search, mobile devices, applications, ads, translation, and more.
RankBrain is Google’s way of using a new NLP search engine system to better serve its users.
The search engine uses natural language processing (or NLP) to parse the query and notices that there is a proper name in two words in the sentence: Joe Perry. … Then search engines use NLP technology to better understand user intent, it is called semantic search.
Natural language searching uses an advanced computer technique called natural language processing (NLP). This process uses large amounts of data to run statistical and machine learning models to infer the meaning of complex grammatical sentences.

